Intro to Time Series Forecasting and Evaluation#
Introduction#
This notebook is the second in two notebooks introducing time series forecasting. The last notebook outlined concepts of time series analysis, such as time series processing, decomposition, correlation and stationarity. This notebook will discuss an intro to time series forecasting and evaluation. Future notebooks will go into depth on specific forecasting methods.
Outline#
Intro to Forecasting
Univariate Forecasting
Exponential Smoothing
Multivariate Forecasting
Forcasting Evaluation
Metrics
Evaluation Methodologies
Conclusion
References
Environment Configuration and Package Imports#
Please Note after installing the dependencies into the notebook you must restart the kernel. Simply, go under the Runtime tab and select Restart and Run All. This must be done only after the first time executing the notebook in a given session.
import sys
in_colab = 'google.colab' in sys.modules
if in_colab:
!pip install darts
!pip install pyyaml==5.4.1
!pip install -U matplotlib
%load_ext autoreload
%autoreload 2
%matplotlib inline
import pywt
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from darts.models import ExponentialSmoothing
from darts import TimeSeries
from darts.datasets import GasRateCO2Dataset
from darts.datasets import AirPassengersDataset
from darts.dataprocessing.transformers import MissingValuesFiller
Intro to Time Series Forecasting#
Univariate Time Series Forecasting#
Univaritate forecasting involves predicting future values given past observations of a time series. More specifically, given a lookback window of length \(T\) and a forecasting horizon of length \(H\), the univariate time series forecasting problem is to find function \(f: \mathbb{R}^{T} \to \mathbb{R}^H\):
where \(x \in \mathbb{R}^T = [y_{1} \cdots y_{T}]\) is an input vector of observations over the lookback window, \(y \in \mathbb{R}^H = [y_{T} \cdots y_{T+H}]\) is the output vector. \(f\) is parametized by \(\theta\) which determine the output \(\hat{y}\) given an input \(x\). \(\theta\) is learned to minimize the prediction loss of the model \(L\) over training portion of the time series. The resulting model \(f\) is evaluated on an unseen portion of the time series to estimate the out-of-sample performance.
To solidify this notion, we will train and evaluate an Exponential Smoothing Forecasting model on the Air Passenger Dataset. The Air Passenger dataset tracks the amount of commercial airplane passengers \(x_i\) by month \(i\). We can use the darts.datasets.AirPassengersDataset.load function to load the dataset:
ts = AirPassengersDataset().load()
ts.plot()
With our dataset in place, we can select a univariate forecasting model to train and evaluate. For this example, we consider an Exponential Smoothing Forecasting model a seminal approach to time series forecasting.
Aside: Exponential Smoothing#
Exponential smoothing (ES) models generate predictions \(\hat{y}\) as linear combination of past observations \(x_1 ,\cdots, x_T\) with exponentially decreasing weights. The implicit assumption of ES models is that the dependence of current observation on previous observations decays across time. In this way, ES models are extremely efficient - requiring only the previous smoothed value and the current time series value to compute a given prediction. This makes them favourable for use cases with low latency requirements. In the following, we will explore some common variation of ES models.
Simple Exponential Smoothing (Brown Method)#
In the simplest case, the smoothed series value at time \(t\), \(l_t\), is a weighted average of the previous smoothed value \(l_{t-1}\) and the current time series value \(x_t\):
Given this, The forecast \(h\) steps ahead is defined by:
which means simply that out of sample, our forecast is equal to the most recent value of the smoothed series. A few things to note about Simple Exponential Smoothing:
Smoothing factor \(\alpha\) controls tradeoff between recency and smoothing
\(\alpha\) can be set manually or estimated
Smoothing needs some time to catch up with the dynamics of your time series. A rule of thumb for a reasonable sample size is that you need \(\frac{3}{\alpha}\) observations.
Double Exponential Smoothing (Holt Method)#
Simple Exponential smoothing gives us an estimate of the level of the time series which acts as an intercept. In Double Exponential smoothing, we add another component into the forecasting function - the trend. Similar to the level, we apply exponential smoothing to the trend by assuming that the future direction of the time series changes depends on the previous weighted changes. This can be expressed as follows:
Given this, the forecast \(h\) steps ahead is defined by
The forecast function is no longer flat but trending: \(h\)-step-ahead forecast is equal to the last estimated level plus \(h\) times the last estimated trend value. A few things to note about Double Exponential Smoothing:
The first equation describes the level of the series which depends on the current value of the series, the previous level value and the previous trend value.
The second equation describes the trend, which depends on the level changes at the current step and on the previous value of the trend.
The values of \(\alpha\) and \(\beta\) are set based on expert judgement or estimated (jointly) from the data.
Triple Exponential Smoothing (Holt-Winters Method)#
A natural extension of Double Exponential smoothing is Triple Exponential Smoothing. In triple exponential smoothing, we include a trend, level as well as a seasonal component with period \(L\) into the forecasting function:
Given this, the forecast \(h\) steps ahead is defined by:
The forecast function consists of a level, trend and seasonal component. A few things to note about Triple Exponential Smoothing:
The seasonal component explains repeated variations around intercept and trend, and it will be specified by the period.
For each observation in the season, there is a separate component; for example, if the length of the season is 7 days (a weekly seasonality), we will have 7 seasonal components value of the trend.
The values of \(\alpha\), \(\beta\) and \(\gamma\) are set based on expert judgement or estimated (jointly) from the data.
We can create an Holt Winters Exponential Smoothing Forecasting Model by initializing the darts.models.ExponentialSmoothing object. Subsequently, the model can be fit by passing the TimeSeries object to the fit method of the initialized model.
es_model = ExponentialSmoothing()
es_model.fit(ts)
<darts.models.forecasting.exponential_smoothing.ExponentialSmoothing at 0x7fa2f8cd0190>
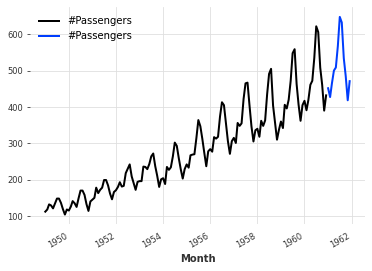
Predictions can be generated from the fit model by calling the predict method with the length of the forecasting horizon as an argument. Here we predict the 12 monthly observations following the data used to fit the model and plot the result in blue:
pred_es = es_model.predict(12)
ts.plot()
pred_es.plot()
Multivariate Forecasting#
Multivariate forecasting involves predicting future values given past observations of a set of time series. More specifically, given a lookback window of length \(T\), a forecasting horizon of length \(H\) and a set of \(K\) time series, the multivariate time series forecasting problem is to find function \(f: \mathbb{R}^{TxK} \to \mathbb{R}^{HxK}\):
where \(X \in \mathbb{R}^{TxK}\) is a matrix where each column is a sequence of observations over the lookback window for a specific time series and \(Y \in \mathbb{R}^{HxK} \) is the output matrix where each column is the output sequence over the forecasting horizon for a specific time series.
Similar to univariate forecasting, \(f\) is paramerized by \(\theta\) which determine the output \(\hat{y}\) given an input \(x\). \(\theta\) is learned to minimize the prediction loss of the model \(L\) over the training portion of the time series. The resulting model \(f\) is evaluated on an unseen portion of the time series to estimate the out-of-sample performance.
This serves as a preliminary discussion of multivariate forecasting. In the following session, methods for multivariate forecasting will be discussed in detail.
Covariates#
Strictly relying on the history of a time series to predict its future is often suboptimal. In these cases, its beneficial to include covariates into the forecasting model. Covariates are exogenous time series that influence target time series. Covariates can be divided into the following two categories:
Past Covariates: time series whose past values are known at prediction time. Those series often contain values that have to be observed to be known.
Future Covariates: Future covariates are time series whose future values are known at prediction time. Often, the past values of future covariates are known as well.
To make this more concrete, the illustration below depicts the relationship between past covariates, future covariates and the target time series:

Only certain forecasting models support exogenous variables such as Neural Prophet, SARIMAX, DeepAR. Some of these methods will be explained in detail in future notebooks.
Forecasting Evaluation#
Metrics#
Once the chosen model has been fit to the dataset, it must evaluated on unseen data to assess the out of sample performance. There are numerous metrics that are used including Mean Absolute Error (MAE), Mean Squared Error (MSE) and Mean Absolute Percentage Error. Given a forecast \(y \in R^N\) and corresponding ground truth \(\hat{y} \in R^N\), the metrics are defined as follows:

The darts.metrics.metrics module contains the aforementioned metrics and more. These metrics can be easily used to evaluate the forecasts generated by our model as we will see below.
Evaluation Methodologies#
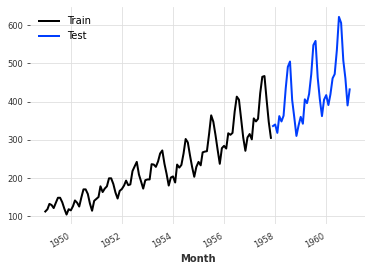
Besides metrics, another central component of evaluation is determine how to split the data into training and testing. The most common approach is to allocate the first portion of the time series to the training set and the latter part to the testing set. This is a familiar data splitting scheme for ML practitioners. It is conservative with respect to to data leakage and generalizability estimation. One downside of this approach is that the model does not learn from the most recent observation. We can split a darts.TimeSeries object in this manner by calling the split_before method with the proportion of the data to be alllocated to the train set.
ts_train, ts_test = ts.split_before(.75)
ts_train.plot(label="Train")
ts_test.plot(label="Test")
We can now fit a model on the train set and subsequently plot the prediction results on the test set:
es_model = ExponentialSmoothing()
es_model.fit(ts_train)
forecast = es_model.predict(36)
ts.plot(label="Actual")
forecast.plot(label="Forecast")
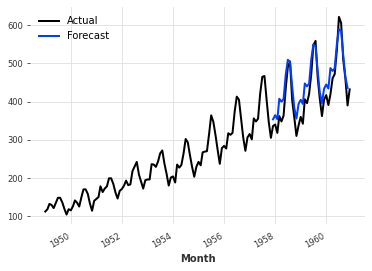
The forecast can be evaluated with the metrics defined in the darts.metrics.metrics. In particular, we will evaulate the forecast using MAE, MSE and MAPE:
from darts.metrics.metrics import mae, mse, mape
mae_score = mae(ts_test, forecast)
mse_score = mse(ts_test, forecast)
mape_score = mape(ts_test, forecast)
print(f"MAE: {mae_score} MSE: {mse_score} MAPE: {mape_score}")
MAE: 30.58656732050072 MSE: 1193.5935888751771 MAPE: 7.812233620065577
Another more sophisticated evaluation methodology is to use rolling cross validation. In rolling cross validation, multiple models are fit and evaluated using different train and test sets. In particular, the datasets are generated using an expanding window approach and the results are averaged to get a single estimate. The illustration below helps depict the concept of rolling cross validation:

In this way, we are evaluating the approach as opposed to a single model. Additionally, unlike the previous evaluation methodology, the model is able to learn from the must recent observations. However, there are many subtle design choices such as how to weight past performance compared to more recent performance. Furthermore, training multiple models is computationally intensive, especially for deep learning based approaches.
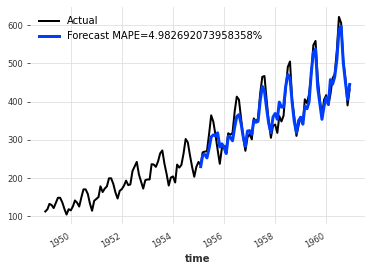
darts makes it easy to realize rolling cross validation using the historical_forecast method of the model. It takes a time series, a starting point and a forecast horizon. It returns the darts.TimeSeries containing the historical forecasts would have been obtained when using the model to forecast the series with the specified forecast horizon, starting at the specified timestamp using an expanding window strategy:
es_model = ExponentialSmoothing()
backtest = es_model.historical_forecasts(ts, start=.5, forecast_horizon=3)
err = mape(backtest, ts)
ts.plot(label="Actual")
backtest.plot(lw=3, label=f"Forecast MAPE={err}%")
Conclusion#
In this notebook an introduction to time series forecasting was provided. Topics we covered include:
Univariate forecasting setup and Multivariate forecasting setup
Including covariates to enhance performance
Metrics to evaulate accuracy of forecasts
Forecasting evaluation methodologies
Resources#
Next Steps#
Apply techniques for time series forecasting to relevant dataset
Explore the univariate forecasting method demos in the forecasting-with-dl repo
Dive deeper into the topics we explored in the following notebooks: