Introduction to Time Series Analysis#
Introduction#
With the advent of big data, an increasing amount of information is being captured by organizations to optimize their operations and enhance their product offerings. Often, this data forms a time series - a sequence of data points indexed by time. Forecasting involves predicting future values given past observations of a time series. Common applications of time series forecasting include predicting future sales, patient outcomes, asset prices and resourcing needs.

This two-part notebook series provides an overview machine learning for time series forecasting. Throughout the series, we will discuss exploratory analysis, data preprocessing, modelling and evaluation. In doing so, we will encounter several time series forecasting methods, from classical statistical approaches (ARIMA, Exponential Smoothing, etc.) to state-of-the-art neural network-based methods (NHITS, Temporal Fusion Transformer, etc.). To illustrate concepts, we will use Python packages such as pandas, statsmodels and darts. The outline for this notebook - Intro to Time Series is below:
Outline#
Intro to Time Series
Basic Time Series Operations
Missing Values
Resampling
Denoising
Time Series Analysis
Autocorrelation and Partial Autocorrelation
Cross Correlation
Time Series Decomposition
Stationairy Data
Making Data Stationairy
Conclusion
References
Next Steps
Environment Configuration and Imports#
IF USING COLAB: After installing the dependencies into the notebook you must restart the kernel. Simply, go under the Runtime tab and select Restart and Run All. This must be done only after the first time executing the notebook in a given session.
import sys
in_colab = 'google.colab' in sys.modules
if in_colab:
!pip install darts
!pip install pyyaml==5.4.1
!pip install -U matplotlib
%load_ext autoreload
%autoreload 2
%matplotlib inline
import pywt
import numpy as np
import pandas as pd
import statsmodels.api as sm
from statsmodels.tsa.stattools import adfuller
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
import matplotlib.pyplot as plt
from darts import TimeSeries
from darts.datasets import GasRateCO2Dataset
from darts.datasets import AirPassengersDataset
from darts.dataprocessing.transformers import MissingValuesFiller
Intro to Time Series#
Time Series data is a sequence of data points indexed by time. In the simplest case, each datapoint \(x_i\) is a scalar in whats referred to as a univariate time series. We can represent a univariate time series with N observations using a value vector \(\mathbf{x} \in R^N\) where the index \(i \dots N\) represent the time step:
In contrast, a multivariate time series has a vector \(X_ i \in R^{M}\) of observations at each time step. In this way, a multivariate time series is a set of time series over the same indices. It follows that multivariate time series are represented as matrices \(X \in R^{NxM}\) where the row index \(i \dots N\) is the time step and the column index \(j \dots M\) is the time series:
Load Univariate Data#
To solidify this notion, we will use the Air Passenger Dataset which is a univariate time series that tracks the amount of commerical airplane passengers \(x_i\) by month \(i\). We can use the darts.datasets.AirPassengersDataset.load function to load the dataset:
ts = AirPassengersDataset().load()
df = ts.pd_dataframe()
df
| component | #Passengers |
|---|---|
| Month | |
| 1949-01-01 | 112.0 |
| 1949-02-01 | 118.0 |
| 1949-03-01 | 132.0 |
| 1949-04-01 | 129.0 |
| 1949-05-01 | 121.0 |
| ... | ... |
| 1960-08-01 | 606.0 |
| 1960-09-01 | 508.0 |
| 1960-10-01 | 461.0 |
| 1960-11-01 | 390.0 |
| 1960-12-01 | 432.0 |
144 rows × 1 columns
Generate Missing Value DF#
val_list = df["#Passengers"].tolist()
null_index_list = [i for i in range(len(df)) if i % 8 == 0]
mv_df = df.copy()
mv_df["#Passengers"][null_index_list] = np.nan
mv_df
| component | #Passengers |
|---|---|
| Month | |
| 1949-01-01 | NaN |
| 1949-02-01 | 118.0 |
| 1949-03-01 | 132.0 |
| 1949-04-01 | 129.0 |
| 1949-05-01 | 121.0 |
| ... | ... |
| 1960-08-01 | 606.0 |
| 1960-09-01 | 508.0 |
| 1960-10-01 | 461.0 |
| 1960-11-01 | 390.0 |
| 1960-12-01 | 432.0 |
144 rows × 1 columns
mv_ts = TimeSeries.from_dataframe(mv_df)
mv_ts.plot()
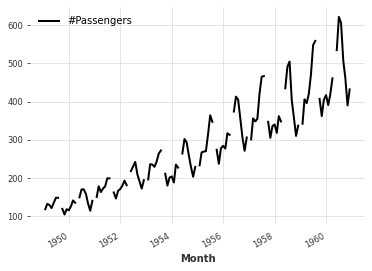
Time Series Operations#
Missing Values#
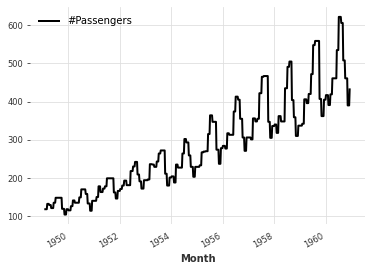
As evidenced by the above plot, there are missing values at some indexes \(i\) in the time series. In general, missing values \(x_i\) can be filled with a previous non-missing value \(x_i\) (forward fill) or a function (average, etc.) of previous non-missing values. It is important to note that missing values should always be filled using a function of previous values to avoid introducting a look-ahead bias. We can apply the pandas.DataFrame.ffill method to the underlying pandas.DataFrame in order to generate the forward filled series:
ffill_df = mv_df.ffill()
ts = TimeSeries.from_dataframe(ffill_df)
ts.plot()

Resampling#
The temporal resolution is the frequency at which the observations in the time series occur. Common temporal resolutions include hourly, daily and weekly data. It is generally assumed the temporal resolution of the time series is constant across observations. We can use resampling to change the temporal cadence of the time series by using upsampling or downsampling.

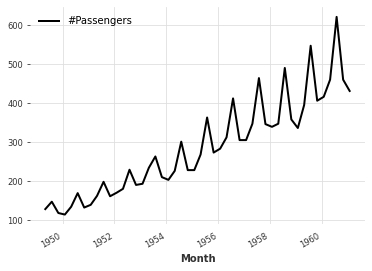
Downsampling: Decreases the frequency of observations by reducing the sampling rate of the input time series. This involves omitting intermediate values \(x_j\) that lie between points \(x_i\) and \(x_k\). More formally, the downsampling operation maps the original time series \(\mathbf{x} \in R^{N}\) to a lower resolution time series \(\mathbf{\hat{x}} \in R^{D}\).
We can downsample the monthly time series to quarterly using the darts.TimeSeries.resample method:
quarterly_series = ts.resample("3M")
quarterly_series.plot()
Upsampling: Increases frequency of observations by genarating intermediate values \(x_j\) by interpolating/filling between adjacent time series values \(x_i\) and \(x_k\). More formally, the upsampling operation maps the original time series \(\mathbf{x} \in R^{D}\) to a higher resolution time series \(\mathbf{\hat{x}} \in R^{N}\).
Similar to downsampling, we can upsample the time series from monthly to weekly data using the darts.TimeSeries.resample method:
weekly_series = ts.resample("1W")
weekly_series.plot()
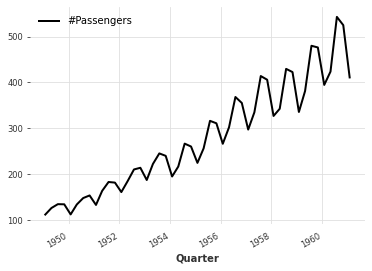
ds_df = df.resample("3M").mean()
print(ds_df.columns)
ds_df.index.names = ["Quarter"]
Index(['#Passengers'], dtype='object', name='component')
ds_ts = TimeSeries.from_dataframe(ds_df)
ds_ts.plot()
us_df = ds_df.resample("1M").ffill()
us_df.index.names = ["Day"]
us_ts = TimeSeries.from_dataframe(us_df)
us_ts.plot()
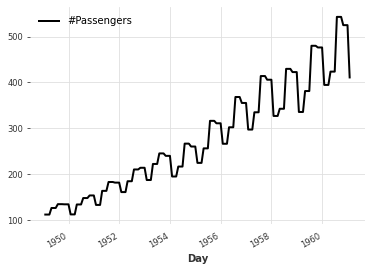
Denoising#
As a stochastic process, time series are vulnerable to noise. It is often helpful to denoise data - a process that involves filtering out noise to extract the underlying signal. There are many approaches to denoising time series data, we will explore just one - Average Smoothing.
Average Smoothing: Average smoothing involves iteratively computing the average over a sliding window of observations that is incremented by a stride across the entire time series. This computation can be realized using average pooling on input time series with padding to ensure the output time series has the same dimensionality:
We can write a custom function to perform the operation on a column of the pandas.DataFrame underlying the darts.TimeSeries object. A new time series can be initialized with the updated dataframe:
def average_smoothing(signal, kernel_size=3, stride=1):
padding_size = kernel_size // 2
padded_signal = np.pad(signal, padding_size)
samples = []
start = 0
while True:
start = start
end = start + kernel_size
val = padded_signal[start:end].mean()
samples.append(val)
start += 1
if end == len(padded_signal):
break
res = np.array(samples)
return res
# Get index and time series
np_ts = df["#Passengers"].to_numpy()
index = df.index
# Average Smoothing
dn_as = average_smoothing(np_ts)
dn_as_df = pd.DataFrame()
dn_as_df.index = index
dn_as_df["#Passengers"] = dn_as
# Plot new time series
dn_as_ts = TimeSeries.from_dataframe=(dn_as_df)
dn_as_ts.plot()
<AxesSubplot: xlabel='Month'>
Time Series Analysis#
Time Series Decomposition#
In time series analysis, it is common to decompose a time series into multiple components representing different factors of variation. These include the trend, cyclical, seasonal and residual (irregular) components.
Trend: General tendency of the time series to increase or decrease over time.
Cyclical: Fluctuations in the values of the time series occuring at irregular intervals.
Periodic: Fluctuations in the values of time series occuring at regular intervals.
Residual: Fluctuations in the values of time series, which are a result of unforeseen and unpredictable forces.
The following figure illustrates the various components of a time series:

It is worth noting that the trend is often lumped together with an intercept term known as the level. Additionally, the cyclical component is usually not included unless it is clear that cycles exist in the time series (ex. economic related time series). With this assumption in place, we can formally specify the interaction of the sub-components of the time series. Two simple models for time series decomposition include additive decomposition and multiplicative decomposition.
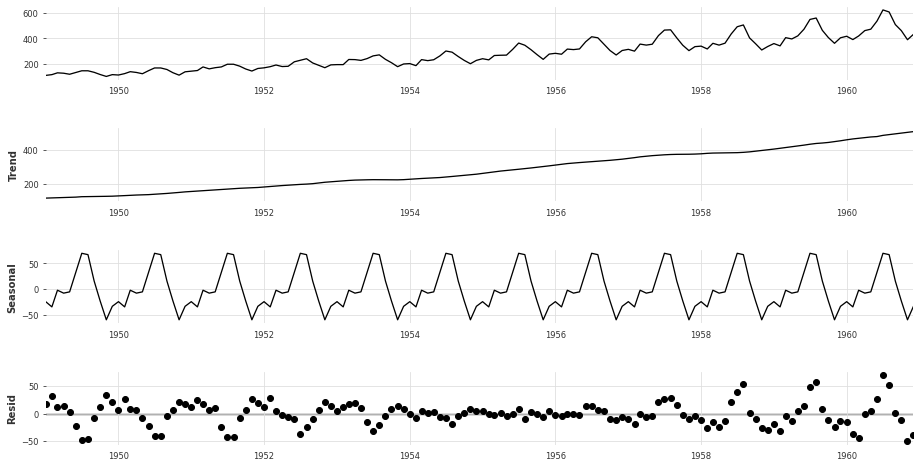
Additive Decomposition: Assumes additive interaction between sub-components of time series. Additive decomposition is most appropriate in the case where the of the seasonal fluctuations are not propostional to the magnitude of the time series (ie trend + level). The additive decomposition can be formally specified as follows:
where \(x_{i}\) is the time series value, \(s_{i}\) is the seasonal componemt, \(t_{i}\) is the trend compenent and \(r_i\) is the residual component, all at time \(i\).
In the case of the Air Passenger time series, the additive decomposition can be performed with the sm.tsa.seasonal_decompose function with model="additive"as follows:
# graphs to show seasonal_decompose
def seasonal_decompose(y, model):
decomposition = sm.tsa.seasonal_decompose(y, model=model, extrapolate_trend='freq')
fig = decomposition.plot()
fig.set_size_inches(14,7)
plt.show()
# Decompose Air Passenger additive
seasonal_decompose(df, model="additive")
Multiplicative Decomposition: Assumes multiplicative interaction between sub-components of the time series. Multiplicative decomposition is most appropriate in the case where the magnitude of the seasonal fluctuations are proportional to the magnitude of the time series (ie trend + level). The multiplicative decomposition can be formally specified as follows:
where \(x_{i}\) is the time series value, \(s_{i}\) is the seasonal componemt, \(t_{i}\) is the trend compenent and \(r_i\) is the residual component, all at time \(i\).
In the case of the Air Passenger time series, the multiplicative decomposition can be performed with the sm.tsa.seasonal_decompose function model="multiplicative" as follows:
# Decompose Ait Passenger Multiplicative
seasonal_decompose(df, model="multiplicative")
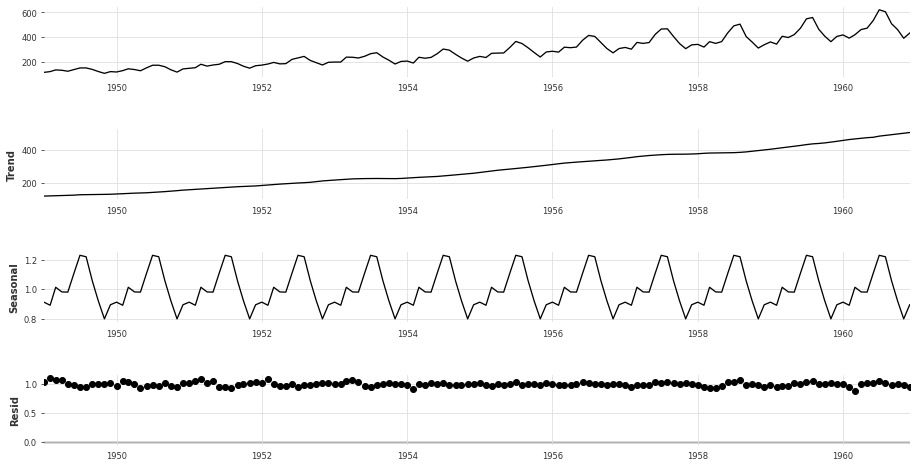
By looking at the plots of the residuals, it is evident that the multiplicative decomposition is more appropriate for this time series. This is due to the fact that the residuals approximate a normal distribution with mean 0. In the case of the additive decomposition, the residuals seem to have underlying patterns, indicating they are not exclusively noise.
Autocorrelation and Partial Autocorrelation#
One central component in time series analysis is discovering the relative dependencies among indices of the time series. To this end, autocorrelation and partial autocorrelation are two metrics that measure this.
Autocorrelation: Correlation of a signal with a lagged version of itself as a function of the delay. Given a time series \(\mathbf{^{t}x}\) and its \(k\) lagged series \(\mathbf{^{t-k}x}\), the autocorrelation \(a_{k}\) can be calculated as follows:
where \(cov\) is a function that computes covariance and \(var\) is a function that computes the variance. By computing the \(A_k\) for all lags from \(1\) to \(K\), we generate a vector \(A \in R^K\) where each entry represents the autocorrelation for a specific lag. In the case of the Air Passenger Dataset, the autocorrelation with \(K=25\) can be plotted using the statsmodels.graphics.tsaplots.plot_acf function.
# Autocorrelation
plot_acf(df['#Passengers'])
print()
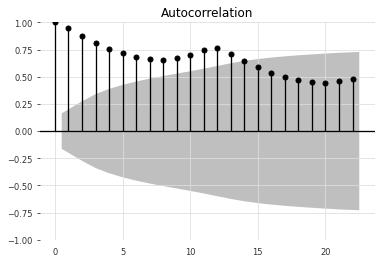
The autocorrelation ranges from -1 (tend to move in the same direction) and 1 (tend to move in different directions). From the above plot, the lag series \(\mathbf{^{t-k}x}\) has the highest autocorrelation, 1, when \(k=0\). This makes sense intuitively because \(\mathbf{^{t}x}\) and \(\mathbf{^{t-k}x}\) are equivalent when \(k=0\). You will also notice a shaded area, which corresponds to the confidence interval. If an autocorrelation value exceeds the confidence interval region, the autocorrelation value is statistically significant.
Partial Autocorrelation: Correlation of a signal with a lagged version of itself as a function of the delay with the relationships of intervening observations removed. Using partial correlation helps derive the dependencies among time steps more accurately by controlling for the effects of other lags. Given a time seres \(\mathbf{^{t}x}\) and its \(k\) lagged series \(\mathbf{^{t-k}x}\), the partial autocorrelation \(p_{k}\) can be calculated as follows:
where \(cov\) is a function that computes covariance between \(\mathbf{^{t}x}\) and \(\mathbf{^{t-k}x}\) conditioned on intermediate values and \(var\) is a function that computes the variance of \(\mathbf{^{t}x}\) and \(\mathbf{^{t}x}\) conditioned on intermediate values. By computing the \(p_k\) for all lags from 1 to 𝐾 , we generate a vector \(\mathbf{p} \in 𝑅^𝐾\) where each entry represents the autocorrelation for a specific lag. In the case of the Air Passenger Dataset, the partial autocorrelation with 𝐾=25 can be plotted using the statsmodels.graphics.tsaplots.plot_pacf function:
# Partial Autocorrelation
plot_pacf(df['#Passengers'])
print()
/ssd003/projects/aieng/public/forecasting_unified/lib/python3.8/site-packages/statsmodels/graphics/tsaplots.py:348: FutureWarning: The default method 'yw' can produce PACF values outside of the [-1,1] interval. After 0.13, the default will change tounadjusted Yule-Walker ('ywm'). You can use this method now by setting method='ywm'.
warnings.warn(
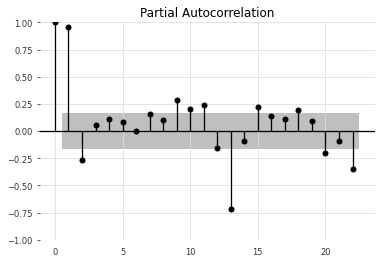
The partial autocorrelation ranges from -1 (tend to move in the same direction) and 1 (tend to move in different directions). In contrast to the autocorrelation plot, the partial autocorrelation plot highlights dependencies based solely on their contribution. You will also notice a shaded area, which corresponds to the confidence interval. If a partial autocorrelation value exceeds the confidence interval region, the partial autocorrelation value is statistically significant.
Cross Correlation#
Often, it is beneficial to compare multiple time series to discover what relationships exist. By generalizing the notion of autocorrelation, we are able to define cross correlation, which describes the relationship between a pair of time series at different lags. To account for the fact that we can compute lags on each time series independently, we have defined positive and negative lags to evaluate the correlation of the two time series. A positive lag in one time series is a negative lag in the other time series and vice versa.
To illustrate the concept of cross-correlation, we can compute an affine transformation on the AirPassenger time series and compute the cross-correlation between the two time series at different lags with a maximum lag of \( K = \pm 10 \). The function matplotlib.pyplot.xcorr is useful for generating a cross-correlation plot for a pair of time series:
passengers = df["#Passengers"]
passengers_shifted = passengers + 10
f, axarr = plt.subplots(1, 1, figsize=(10, 5))
axarr.xcorr(passengers, passengers_shifted, maxlags=10, normed=True)
axarr.set_title("Cross Correlation Plot")
axarr.set_xlabel("Lag")
axarr.set_ylabel("Correlation")
axarr.plot()
[]
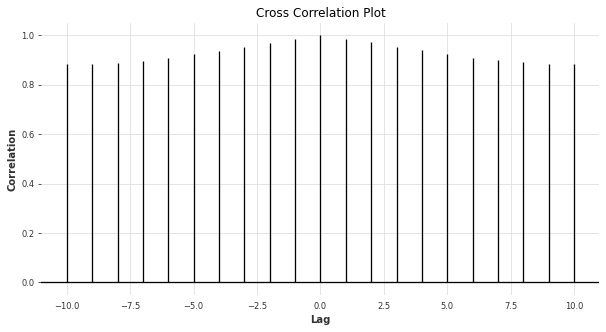
Stationarity#
Many techniques for time series forecasting assume that the underlying time series is stationary. A stationary time series has constant mean and variance over time. In many cases, time series are not stationary. As a quick check, we can determine if a given time series is stationary by visualizing the mean and variance as a function of time.
In the case of the Air Passenger time series, the visualization can be generated as follows:
### plot for Rolling Statistic for testing Stationarity
def test_stationarity(timeseries, title):
#Determing rolling statistics
rolmean = pd.Series(timeseries).rolling(window=12).mean()
rolstd = pd.Series(timeseries).rolling(window=12).std()
fig, ax = plt.subplots(figsize=(16, 4))
ax.plot(timeseries, label= title)
ax.plot(rolmean, label='rolling mean');
ax.plot(rolstd, label='rolling std (x10)');
ax.legend()
test_stationarity(df["#Passengers"], "")
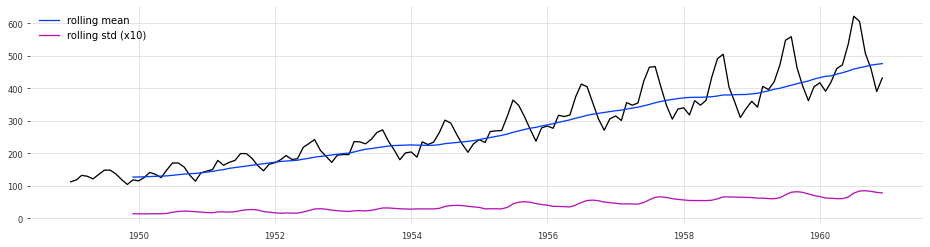
Clearly, the time series is not stationary because both the standard deviation and the mean change across time. In some cases, it may not be apparent from such a visualization, so we can resort to statistical tests to determine whether or not the time series is stationairy. On such statistical test is the Augmented Dickey-Fuller Test, which can be implemented using the statsmodels.tsa.stattools.adfuller function as follows:
# Augmented Dickey-Fuller Test
def ADF_test(timeseries, dataDesc):
print(' > Is the {} stationary ?'.format(dataDesc))
dftest = adfuller(timeseries.dropna(), autolag='AIC')
print('Test statistic = {:.3f}'.format(dftest[0]))
print('P-value = {:.3f}'.format(dftest[1]))
print('Critical values :')
for k, v in dftest[4].items():
print('\t{}: {} - The data is {} stationary with {}% confidence'.format(k, v, 'not' if v<dftest[0] else '', 100-int(k[:-1])))
ADF_test(df["#Passengers"], "Air Passenger Time Series")
> Is the Air Passenger Time Series stationary ?
Test statistic = 0.815
P-value = 0.992
Critical values :
1%: -3.4816817173418295 - The data is not stationary with 99% confidence
5%: -2.8840418343195267 - The data is not stationary with 95% confidence
10%: -2.578770059171598 - The data is not stationary with 90% confidence
Making Data Stationary#
Their are several methods to make time series data stationary. This is required in cases that you are employing a time series analysis method that assumes there is constant mean and covariance across the entire time series. The time series methods explored in this section are detrending and differencing.
Detrending: Involves subtracting out the underlying trend in the time series to generate the detrended series. The trend can be determined using an average smoothing or other methods. In the case of the Air Passenger Dataset, we can process the time series by detrending it. Subsequently, we can evaluate whether the detrended time series is stationary:
# Detrending
y = df["#Passengers"]
y_detrend = (y - y.rolling(window=12).mean())/y.rolling(window=12).std()
test_stationarity(y_detrend,'de-trended data')
ADF_test(y_detrend,'de-trended data')
> Is the de-trended data stationary ?
Test statistic = -2.481
P-value = 0.120
Critical values :
1%: -3.4865346059036564 - The data is not stationary with 99% confidence
5%: -2.8861509858476264 - The data is not stationary with 95% confidence
10%: -2.579896092790057 - The data is not stationary with 90% confidence
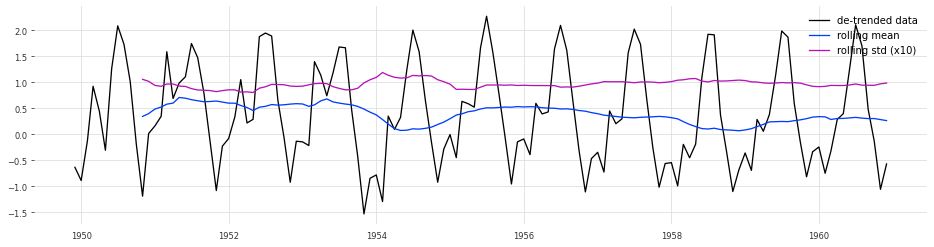
Although the ADF test does not currently consider the time series to be stationary, it is a significant improvement over the original time series.
Differencing: Removes underlying cyclical and seasonal patterns by subtracting out a lagged value of the series. In the case of the Air Passenger Dataset, we can process the time series by differencing it. Subsequently, we can evaluate whether the differenced time series is stationary:
# Differencing
y_12lag = y - y.shift(12)
test_stationarity(y_12lag,'12 lag differenced data')
ADF_test(y_12lag,'12 lag differenced data')
> Is the 12 lag differenced data stationary ?
Test statistic = -3.383
P-value = 0.012
Critical values :
1%: -3.4816817173418295 - The data is not stationary with 99% confidence
5%: -2.8840418343195267 - The data is stationary with 95% confidence
10%: -2.578770059171598 - The data is stationary with 90% confidence
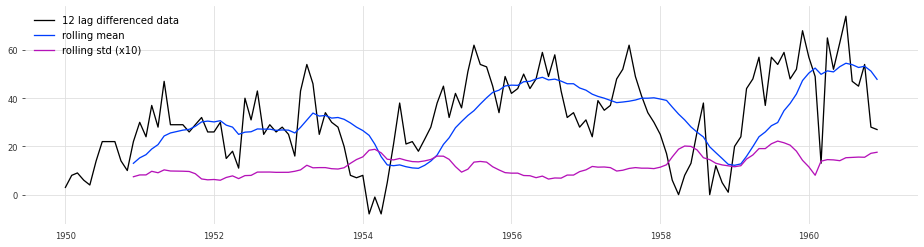
By using differencing, the processed time series is considered stationary. Although for the highest confidence interval, it is not deemed stationary. To mitigate this, we can explore other methods for making the data stationary or combining differencing and detrending to hopefully yield more robust results.
# Detrending and Differencing
y_12lag_detrend = y_detrend - y_detrend.shift(12)
test_stationarity(y_12lag_detrend,'12 lag differenced de-trended data')
ADF_test(y_12lag_detrend,'12 lag differenced de-trended data')
> Is the 12 lag differenced de-trended data stationary ?
Test statistic = -3.181
P-value = 0.021
Critical values :
1%: -3.4924012594942333 - The data is not stationary with 99% confidence
5%: -2.8886968193364835 - The data is stationary with 95% confidence
10%: -2.5812552709190673 - The data is stationary with 90% confidence
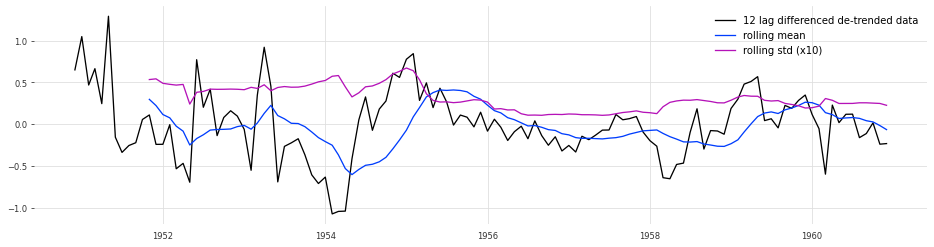
Conclusion#
In this notebook, univariate time series analysis is explored. Topics we covered include:
Basic Time Series operations such as imputing missing values, resampling and denoising.
Discovering dependencies between steps of a time series with autocorrelation and partial autocorrelation.
Discovering dependencies between steps of a pair of time series with cross-correlation.
Decomposing a time series into trend, seasonal, cyclical and residual components
Determining if a series is stationary and methods for making data stationary.
Resources#
Next Steps#
Apply techniques for time series analysis to the dataset for your use case (or similar open source dataset)
Dive deeper into the topics we explored in the following notebook: TS-0: The Basics