
Accountable Deployment of Agentic AI Demands Layered, System-Level Interpretability
When an agentic system fails, who is accountable and how do we determine why? Unlike static models that produce isolated predictions, agentic systems plan, use tools, maintain memory, and coordinate actions over time. Failures may arise not only from incorrect outputs, but from evolving internal state and errors across components that are difficult to trace.
Position
Agentic AI systems behave through trajectories: they plan, invoke tools, update memory, and coordinate over multiple steps. However, interpretability remains largely model-centric, focused on explaining single predictions rather than tracing long-horizon behavior and responsibility across interacting components. As a result, critical failures, such as tool misuse, coordination breakdowns, or goal drift, often evade existing audits until harm occurs.
The interpretability field is solving the wrong problem for the agentic era. Current methods explain how individual models compute outputs but cannot explain why an agent selected a particular plan, how multi-agent coordination failed, or where accountability lies within a system. We argue three points: (1) interpretability methods must co-evolve with agentic capabilities rather than follow them, embedding transparency into planning, tool use, and memory from the outset; (2) agentic opacity occurs at distinct layers such as behavioral, mechanistic, coordination, and safety, each requiring tailored methods; and (3) interpretability must integrate across the full agent development lifecycle rather than serve as a one-time audit.
Alternative Views
Interpretability for agentic systems should come after mature architectures are developed. Investing too early may not help, since future agents could rely on very different representations. This invokes Polanyi's Paradox—agents can be competent without being able to explicitly explain how they do so.
Detailed interpretability is not required for safe deployment. Alignment can be achieved through RLHF, constitutional objectives, and rigorous black-box evaluation. Strong performance on benchmarks and behavioral checks are sufficient to build trust.
Agentic systems should be explained as integrated wholes rather than decomposed into separate layers. Separating behavioral, mechanistic, coordination, and safety layers may obscure tightly coupled interactions and produce fragmented explanations that miss cross-layer dependencies.
Continuous integration across the deployment lifecycle is impractical. Runtime logging, monitoring, and tracing can add computational overhead, increase latency, and complicate deployment in multi-agent systems operating under real-time constraints.
Our Proposal: ATLIS Framework
To operationalize this position, we introduce ATLIS (Agentic Trajectory and Layered Interpretability Stack), a framework integrating five interpretability layers across a five-stage deployment lifecycle. ATLIS enables lightweight continuous monitoring with risk-aware escalation to deeper system-level analysis when incidents are detected. ATLIS provides a blueprint for closing the growing gap between agentic capabilities and the interpretability infrastructure needed to govern them.
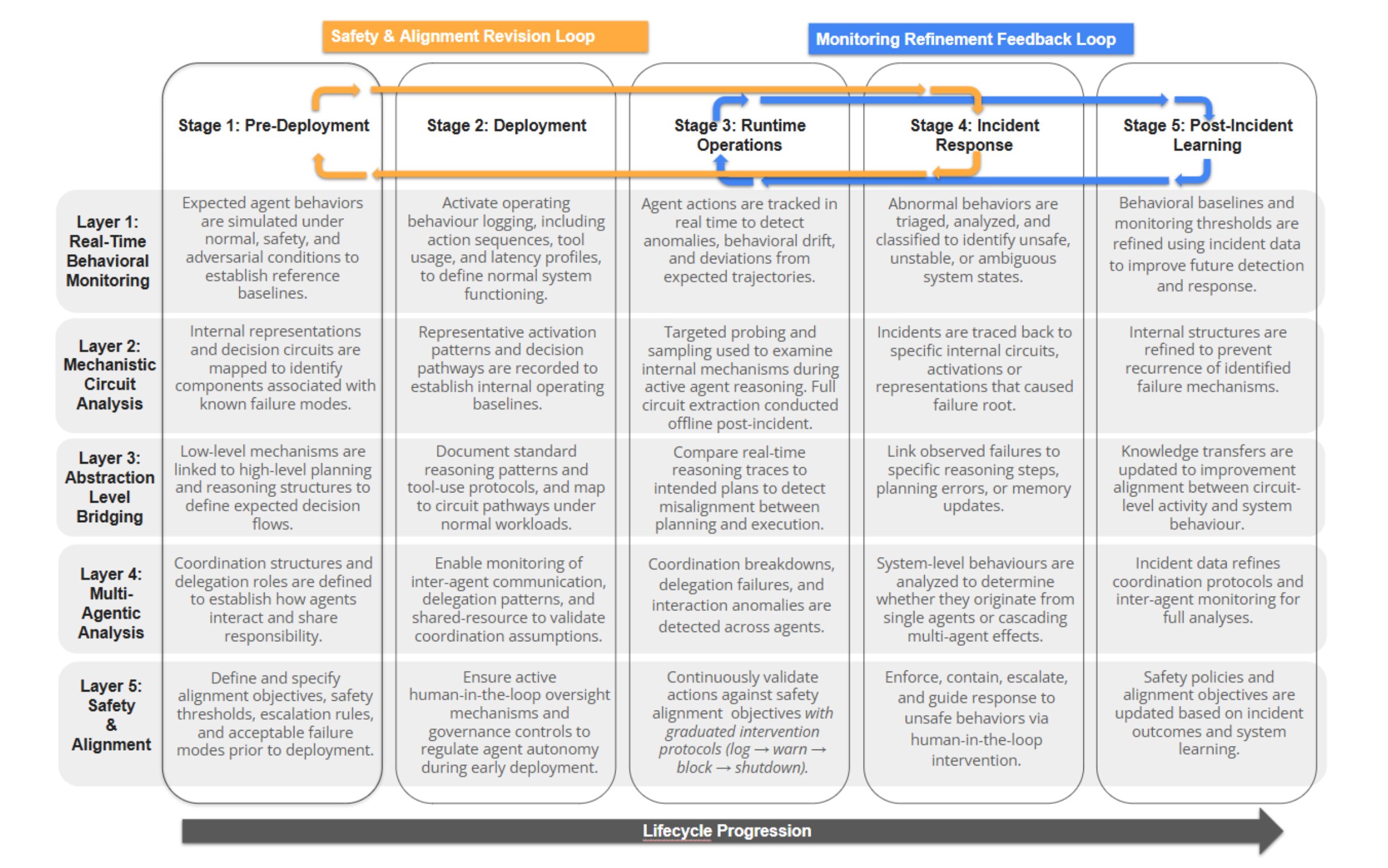
assets/ATLIS-framework_page-0001.jpg. Check filename + capitalization.
Example: Palliative Care Referral
To ground ATLIS in practice, consider a hospital deploying an agentic system design to support palliative care referral for patients with treatment-resistant cancer. The hospital runs two separate systems each in different disease sites: lung and gastrointestinal (GI). Each site uses the same agentic referral workflow, with recommendations routed to clinicians for approval and audit logging. Figure 2 illustrates this diagnostic pathway, showing how ATLIS layers activate across the lifecycle to detect, trace, and resolve the referral timing divergence.
🔴 The Divergence
Despite identical referral criteria and subagent architectural components, the lung site deployment begins referring patients later than the GI site deployment for matched risk profiles. In one system, short-term symptoms improvement stored in memory delays escalation; in the other, accumulated hospitalizations trigger earlier referral. The divergence emerges only over time, due to differences in how longitudinal evidence is stored and propagated through monitoring and planning.
🟢 How ATLIS Surfaces the Divergence
ATLIS surfaces this drift before it causes harm at Layer 1 flagging a systematic delay in lung referrals relative to GI for comparable patients. It then traces the root cause through Layers 2–4 using inter-agent coordination signals and mechanistic differences. This pinpoints the divergence to differences in memory weighting and inter-agent handoff dynamics.
Layer 3 maps these differences in symptom versus hospitalization weighting to divergent clinical reasoning pathways, while Layer 5 evaluates whether referral timing remains within prescribed safety bounds and escalates borderline cases for human-in-the-loop clinician review.
Because ATLIS is embedded across the deployment lifecycle, these findings feed back into updated simulations (pre-deployment), refined runtime baselines (operations), and recalibrated orchestration policies (post-incident learning), enabling continuous system correction rather than one-time diagnosis.
⚠️ Why Model-Centric Methods Would Fail Here
Model-centric interpretability would likely miss this failure. Feature attribution methods (e.g., SHAP or Integrated Gradients) explain individual predictions, but the divergence arises from longitudinal interactions between monitoring, memory, planning, and referral timing. Chain-of-thought inspection or single-agent circuit analysis may appear locally consistent, while the true cause lies upstream in memory updates and cross-agent handoff dynamics. Without behavioral drift baselines and coordination-level analysis, the system-level mechanism would remain hidden.
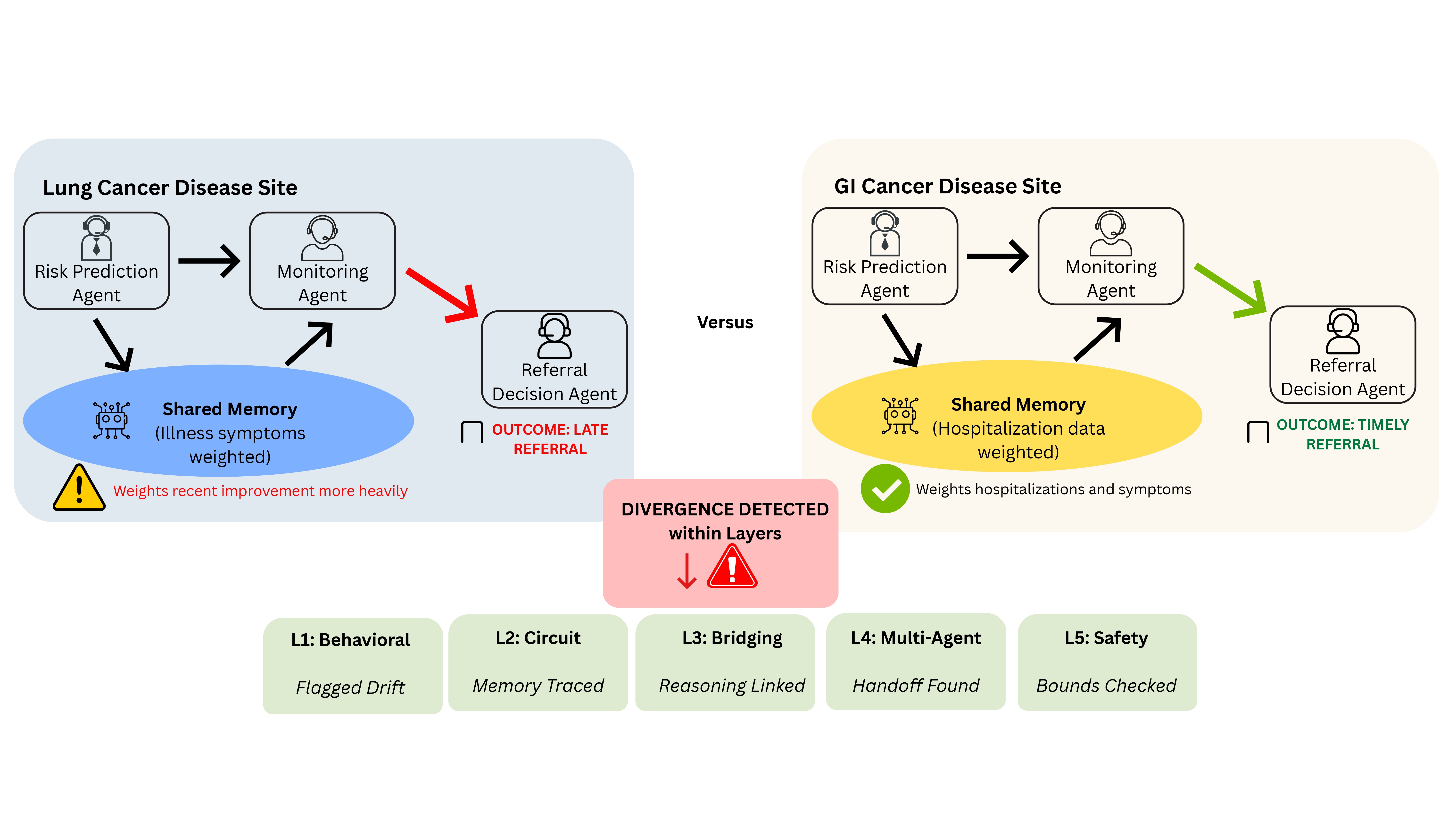
assets/Illustrative Example Diagram_page-0001.jpg. Check spaces + capitalization.
Call to Action and Implementation Plan
Adopting system-centric interpretability for agentic systems raises several priority research directions and has broader implications requiring concerted effort from interdisciplinary groups.
🔬 Research Directions
System-Level Attribution
Current interpretability methods attribute outputs to model internals, but agentic outcomes emerge from multi-step trajectories spanning planning, memory, tool use, and delegation. New attribution methods are needed that track how decisions propagate across components over time, including formal causal frameworks for responsibility assignment in multi-component systems and techniques for reconstructing decision paths under partial observability.
Scalable Runtime Monitoring
Mechanistic analysis remains computationally prohibitive for continuous deployment. Lightweight alternatives are needed, such as multi-resolution observability that logs coarse artifacts continuously while reserving expensive analysis for flagged episodes, minimal sufficient statistics for drift detection, and selective activation strategies that trigger deeper interpretability only when risk thresholds are exceeded.
Benchmarks & Evaluation
There is a lack of standardized resources for evaluating system-centric interpretability. Progress requires shared benchmarks capturing agentic phenomena (coordination failures, goal drift, emergent behaviors), common logging schemas, trajectory datasets with ground-truth failure annotations, and evaluation protocols for multi-agent settings.
🌐 Broader Implications
For Academia
Formalize this stack as a modular research object to test methods across orchestration and memory layers, publish reproducible reference architectures, and log standards.
For Practitioners
Build traceability instrumentation at each module boundary to clarify why specific plans or tool actions occur. This supports guardrail implementation around tool use under uncertainty.
For Regulators
Shift compliance standards to require system-level evidence, such as mandating tracing requirements, full lifecycle monitoring plans, and decision provenance as part of approval or procurement processes, rather than relying solely on model performance metrics.
For Organizations
Perceive agentic systems as continuously governed entities, adopting layered auditing and incident response loops as core acceptance criteria. Encourage shared learning mechanisms, such as standardized incident taxonomies, to encourage proactive interpretability integration within deployed agentic systems and earlier disclosures of failures.
Citation
Use the BibTeX below to cite this work.
@article{zhu2026interpretability,
title={Accountable Deployment of Agentic AI Demands Layered, System-Level Interpretability},
author={Judy Zhu and Dhari Gandhi and Ahmad Rezaie Mianroodi and Dhanesh Ramachandram and Sedef Akinli Kocak and Shaina Raza},
journal={TechRxiv},
doi={10.36227/techrxiv.177069676.68687733/v1},
year={2026}
}