

Abstract
Financial chart question answering in regulated settings demands more than accuracy: practitioners must know which answers to trust before acting on them, and many institutions cannot send client data to external model providers. Yet existing chart-QA agents are accuracy-focused and opaque, and most assume proprietary API access; none is both auditable and deployable on-premise.
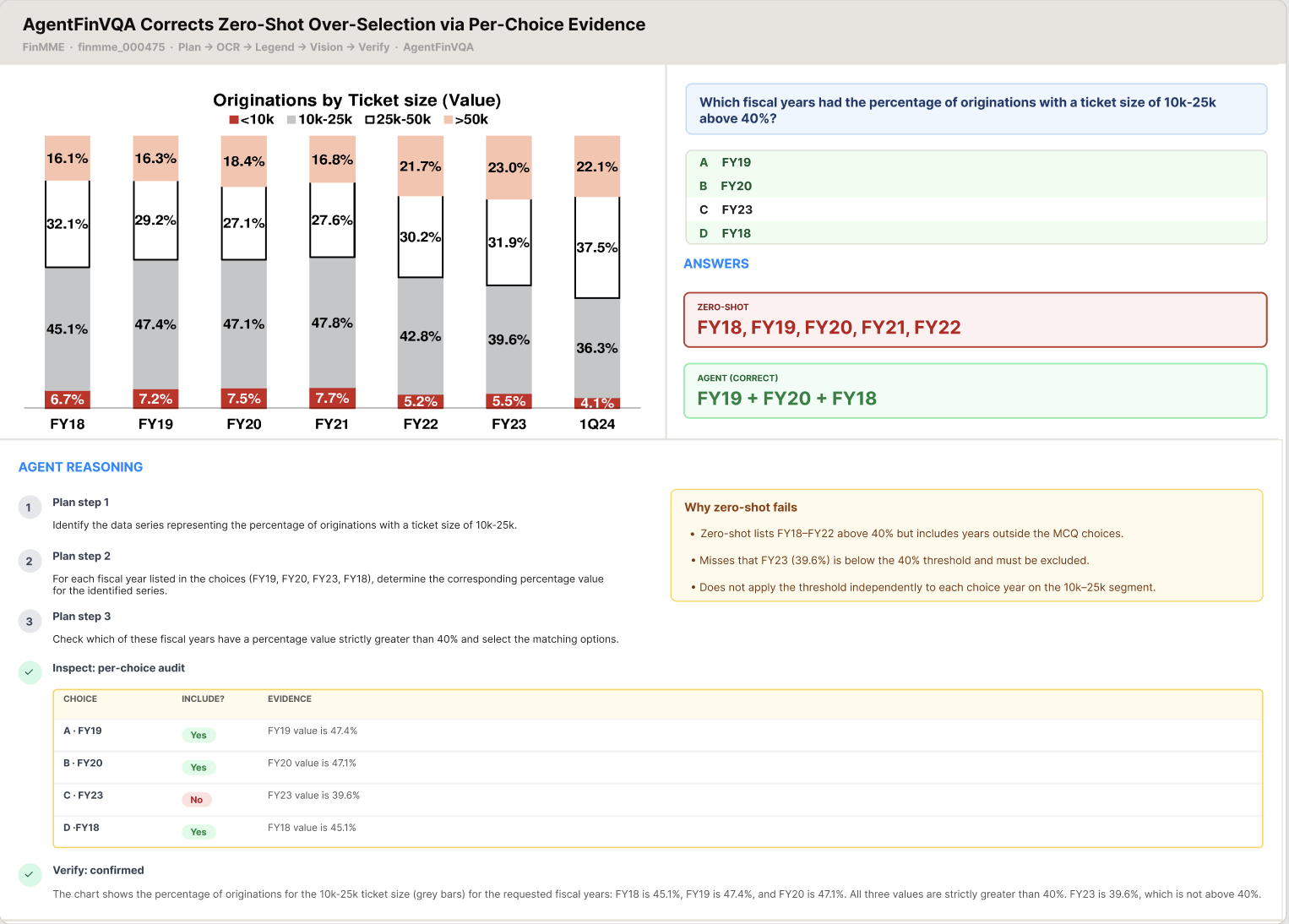
We present AgentFinVQA, a multi-agent pipeline that decomposes each query into planning, OCR, legend grounding, visual inspection, and verification, recording every step in a traceable Model Evaluation Packet (MEP) per sample. On FinMME, AgentFinVQA improves +7.68 pp over a model-matched zero-shot baseline with a proprietary backbone (Gemini-3; 71.24% vs. 63.56%, McNemar p ≈ 1 × 10⁻¹⁶), and +4.84 pp with open-weights Qwen3.6-27B-FP8 served locally on a single A100 at roughly one-tenth the cost, so the gains do not depend on a proprietary API.
The verifier's verdict also serves as a useful confidence signal (68.2% vs. 55.6% exact accuracy on confirmed vs. revised answers), enabling human-in-the-loop review routing. Together these results show that auditable, on-premise financial chart QA is practical and that the open-weights system keeps most of the accuracy gains at a fraction of the cost. We release our code and per-sample MEPs to support reproducible evaluation.
Method
AgentFinVQA coordinates four specialized components in a structured pipeline. Unlike single-pass VLM approaches, each component has a clearly scoped role, and the entire execution trace is captured for post-hoc explainability.
PlannerAgent
Text-only LLM that generates a structured JSON inspection plan — without seeing the image. Separates strategic reasoning from visual perception.
OcrReaderTool
Focused VLM call that transcribes all visible chart text (axes, labels, legend, annotations) into structured JSON, grounding downstream agents in observed text rather than hallucinated values.
VisionAgent
CrewAI-orchestrated agent that executes the planner's steps using vision_qa_tool
to produce a draft answer and explanation.
VerifierAgent
Second VLM that critically reviews the draft answer against the chart image and issues a CONFIRM or REVISE verdict with confidence score.
Model Evaluation Packet (MEP)
Portable JSON artifact capturing the full trace: inspection plan, OCR output, vision reasoning, verifier critique, tool call logs, timestamps, and per-stage errors. Enables reproducible evaluation and model comparison across backends.
Supported Backends
All agents support swappable VLM backends via a unified interface:
- Gemini — Google Gemini 3 Flash / 2.5 Flash (default)
- OpenAI-compatible — GPT-4o, or any locally-served model via vLLM (e.g. Qwen3.5 / Qwen3.6)
- Planner and Verifier can use different backends from the VisionAgent
Dataset
FinMME
AgentFinVQA is evaluated on FinMME, a challenging financial multimodal benchmark spanning 18 financial domains and 6 asset classes. Samples are sourced from real-world financial research reports and cover three cognitive levels, comprehensive understanding, fine-grained perception, and analysis & reasoning, validated by 20 expert annotators.
- 10 major chart types, 21 subtypes (bar, line, pie, candlestick, and more)
- 3 cognitive levels: comprehensive understanding, fine-grained perception, analysis & reasoning
- 3 knowledge domains: equity research, macroeconomic research, assets & financial products
Dataset at a Glance
Results
AgentFinVQA consistently outperforms same-model zero-shot baselines across both evaluated backbones on FinMME. With Gemini-3 Flash the agent gains +7.68 pp mean accuracy (p ≈ 1.1 × 10⁻¹⁶); with the locally-served Qwen3.6-27B-FP8 (vLLM) it gains +4.84 pp (p ≈ 3.0 × 10⁻⁶), demonstrating backend-agnostic improvements.
| System | Backbone | Mean Acc. ↑ |
Exact Acc. ↑ |
MCQ Mean ↑ |
Std Mean ↑ |
|---|---|---|---|---|---|
| Zero-shot | Gemini-3 Flash Preview | 63.56% | 56.40% | 64.4% | 54.0% |
| AgentFinVQA | Gemini-3 Flash Preview | 71.24% | 65.12% | 72.5% | 57.0% |
| Δ | +7.68 pp | +8.72 pp | +8.1 pp | +3.0 pp | |
| Zero-shot | Qwen3.6-27B-FP8 | 61.68% | 53.52% | 62.8% | 49.0% |
| AgentFinVQA | Qwen3.6-27B-FP8 | 66.52% | 60.24% | 68.1% | 48.0% |
| Δ | +4.84 pp | +6.72 pp | +5.3 pp | −1.0 pp† |
FinMME train split (MCQ n = 9,247; Standard n = 1,862). McNemar p ≈ 1.1 × 10⁻¹⁶ (Gemini-3) and p ≈ 3.0 × 10⁻⁶ (Qwen3.6-FP8). †Standard Δ for Qwen is within noise (CI ≈ ±10 pp); treat as exploratory.
Key Findings
- +7.7 pp over same-model zero-shot on FinMME (1,250 matched samples, statistically significant at p < 10⁻¹⁵).
- Multi-select MCQ accuracy improved from 30.2% → 53.5% (+23.3 pp) by giving each agent a dedicated multi-select reasoning path.
- Verifier adds value: removing the VerifierAgent drops accuracy by ~1.2 pp; revised samples achieve 55.6% exact accuracy vs 68.2% on confirmed samples, confirming the verifier correctly targets harder items.
Quick Start
Installation
git clone https://github.com/VectorInstitute/AgentFinVQA.git
cd AgentFinVQA
# Core dependencies
uv sync
# Agentic pipeline (CrewAI, Gemini, Streamlit dashboard)
uv sync --group agentic-xai-eval
source .venv/bin/activate
cp .env.example .env # fill in API keysRun the Pipeline
# Generate MEPs for a dataset split
uv run --env-file .env -m agentfinvqa.runner.run_generate_meps \
--dataset finmme \
--split test \
--n 200 \
--config openai_gemini \
--workers 8 \
--out meps/
# Evaluate and summarize
uv run -m agentfinvqa.eval.summarize --mep-dir meps/
# Launch interactive dashboard
uv run streamlit run src/agentfinvqa/eval/dashboard.py -- --mep-dir meps/BibTeX
If you use AgentFinVQA in your research, please cite:
@misc{narayanan2026agentfinvqadeployablemultiagentpipeline,
title={AgentFinVQA: A Deployable Multi-Agent Pipeline for Auditable Financial Chart QA},
author={Aravind Narayanan and Shaina Raza},
year={2026},
eprint={2606.19782},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2606.19782},
}Acknowledgements
Resources used in preparing this research were provided, in part, by the Province of Ontario and the Government of Canada through CIFAR, as well as companies sponsoring the Vector Institute (vectorinstitute.ai/#partners).
This research was funded by the European Union's Horizon Europe research and innovation programme under the AIXPERT project (Grant Agreement No. 101214389), which aims to develop an agentic, multi-layered, GenAI-powered framework for creating explainable, accountable, and transparent AI systems.